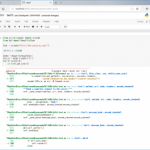
BeautifulSoupを使用したスクレイピングのサンプルです。
ページにアクセスして、h1タグを表示します。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.sakutyuu.com/")
bsObj = BeautifulSoup(html.read())
print(bsObj.h1)
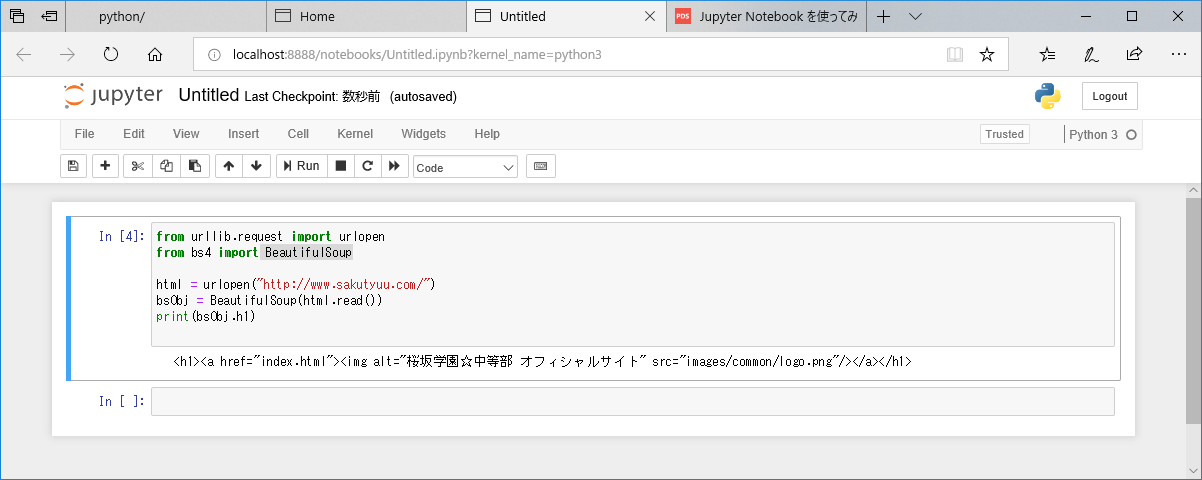
タグを検索し、テキストを取得する。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.sakutyuu.com/")
bsObj = BeautifulSoup(html)
h1List = bsObj.findAll("h1")
for h1 in h1List:
print(h1.get_text())