PythonでBeautifulSoupを使用しWEBスクレイピングするサンプルです。
今回はhttpにアクセスするがエラーとなった場合の例外処理を前回のサンプルに実装します。
前回のサンプル
例外処理はJavaやC#と同様にtry文で実装します。
エラーで考えられる処理を実装しますが、今回はURLが存在しない場合や、HTTP通信時になんらかしらの原因で
エラーなった場合の対処です。
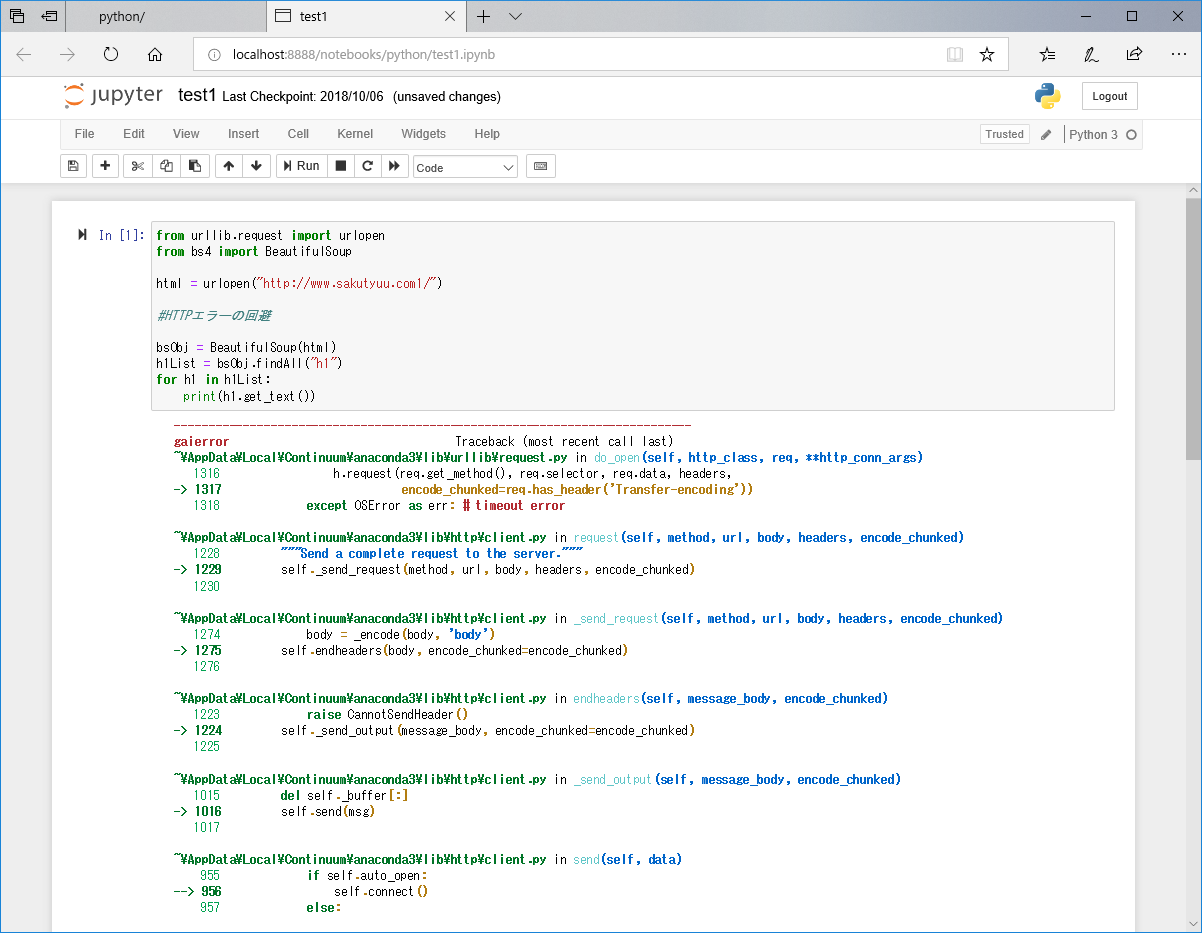
エラーとなった場合に、例外処理をいれないと以下の様になります。
①インポートの追加
from urllib.error import HTTPError
from urllib.error import URLError
➁インポートしたパッケージでエラー処理を追加
実装ソースは以下です。
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.error import HTTPError
from urllib.error import URLError
try:
html = urlopen("http://www.sakutyuu.com1/")
except HTTPError as e:
#エラーの場合の処理
print(e)
except URLError as e:
#エラーの場合の処理
print("URLに接続するが処理できない")
else:
bsObj = BeautifulSoup(html)
h1List = bsObj.findAll("h1")
for h1 in h1List:
print(h1.get_text())
例外処理実装後は以下のキャプチャーの表示となります。